项目设想
偶然发现一个宝藏壁纸网站:Desktop wallpapers hd, free desktop
backgrounds (wallpaperscraft.com)
有很多好看的壁纸供我们免费下载。我便萌生了坏念头:小孩子才做选择,我全都要。
观察网站构造
观察网址规律
打开网站某一页面,比如Anime
wallpapers 4k ultra hd 16:10, desktop backgrounds hd, pictures and
images (wallpaperscraft.com)
先观察网址,它的页面是由https://wallpaperscraft.com/catalog/anime/3840x2400/和page1、page2、page3……依次递增。
获取详情页网址
点击右键,检查元素(或F12)。
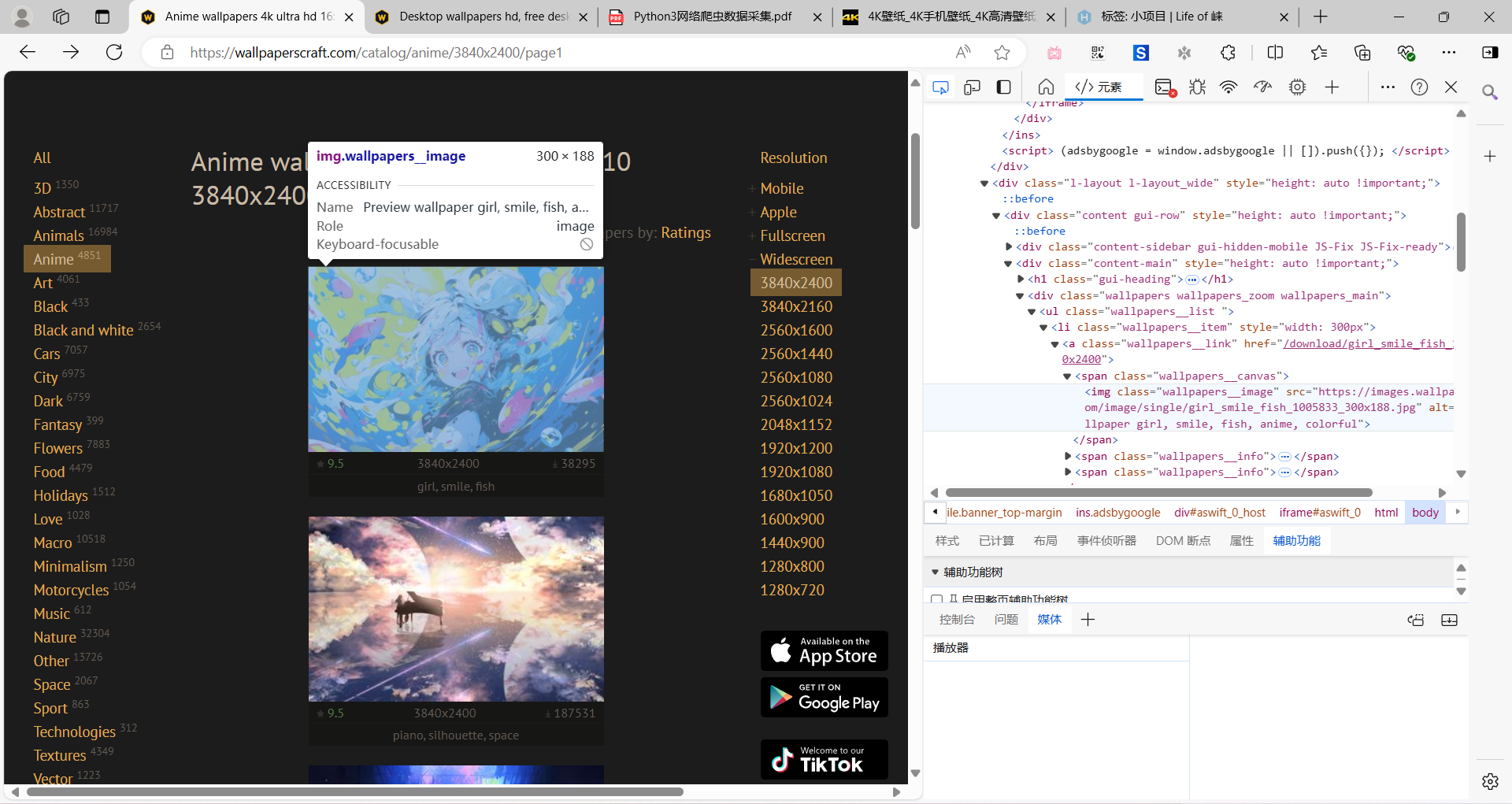 检查元素.png
检查元素.png
我们发现每一张壁纸都在
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| <a class="wallpapers__link" href="/download/girl_smile_fish_1005833/3840x2400">
<span class="wallpapers__canvas">
<img class="wallpapers__image" src="https://images.wallpaperscraft.com/image/single/girl_smile_fish_1005833_300x188.jpg" alt="Preview wallpaper girl, smile, fish, anime, colorful">
</span>
<span class="wallpapers__info">
<span class="wallpapers__info-rating">
<span class="gui-icon gui-icon_rating"></span> 9.5
</span>
3840x2400
<span class="wallpapers__info-downloads">
<span class="gui-icon gui-icon_download"></span> 38295
</span>
</span>
<span class="wallpapers__info">girl, smile, fish</span>
</a>
|
元素中。
这里只展示了壁纸的缩略图,我们想要下载全尺寸的壁纸,必须点进详情页中,也就是<a class="wallpapers__link" href="/download/girl_smile_fish_1005833/3840x2400">中显示的网址:https://wallpaperscraft.com/+/download/girl_smile_fish_1005833/3840x2400
从详情页中下载图片
上一步,我们获得了详情页:https://wallpaperscraft.com/download/girl_smile_fish_1005833/3840x2400
打开,检查元素:
 详情页-检查元素.png
详情页-检查元素.png
我们发现,图片的地址包含在
1
2
3
4
5
| <div class="wallpaper__placeholder">
<a class="JS-Popup" href="https://images.wallpaperscraft.com/image/single/girl_smile_fish_1005833_3840x2400.jpg">
<img class="wallpaper__image" src="https://images.wallpaperscraft.com/image/single/girl_smile_fish_1005833_3840x2400.jpg" alt="3840x2400 Wallpaper girl, smile, fish, anime, colorful">
</a>
</div>
|
元素中。
开始爬虫
磨刀不误砍柴工,观察了这么久,我们终于可以开心地敲代码了。
导入所需库
我们需要的库很简单:urllib和BeautifulSoup。
1
2
| from urllib.request import urlopen
from bs4 import BeautifulSoup
|
获取详情页地址
编写函数:
1
2
3
4
5
| def getDetail(url):
html = urlopen(url)
bsObj = BeautifulSoup(html.read(), features="lxml")
detailLst = bsObj.findAll("a", {"class": "wallpapers__link"})
return ["https://wallpaperscraft.com" + i.attrs["href"] for i in detailLst]
|
bsObj.findAll("a", {"class": "wallpapers__link"})用于将含有详情页地址的元素放入列表detailLst中。
标签对象的href属性是我们所需要的详情页地址,我们通过.attrs["href"]来获取,最后加上前缀"https://wallpaperscraft.com"将完整地址返回。
从详情页中获取全尺寸图片地址
1
2
3
4
5
| def getImg(url):
html = urlopen(url)
bsObj = BeautifulSoup(html.read(), features="lxml")
imgUrl = bsObj.findAll("img", {"class": "wallpaper__image"})[0].attrs["src"]
return imgUrl, imgUrl.split("/")[-1]
|
同上一部分理,我们只需稍作修改。
用imgUrl.split("/")[-1]返回下载图片的名称(包含后缀)。
下载图片
现在万事具备,下载图片就很简单了:
只需要:
1
| from urllib.request import urlretrieve
|
先下载一张图片试试:
1
2
3
4
| m, n = getImg("https://wallpaperscraft.com/download/girl_smile_fish_1005833/3840x2400")
print("Downloading:", n)
urlretrieve(m, n)
print("Done.")
|
收官:批量爬虫
使用循环,这一切就简单多了:
一共52页,我们也没必要全下载。下个10页就差不多了。
1
2
3
4
5
6
7
8
9
10
11
12
| for num in range(1, 11):
try:
target = f"https://wallpaperscraft.com/catalog/anime/3840x2400/page{num}"
detailLst = getDetail(target)
print("\033[91mDownloading from:\033[0m", target)
for details in detailLst:
address, name = getImg(details)
print("Downloading:", name)
urlretrieve(address, "downloaded\\" + name)
print("Done.")
except:
pass
|
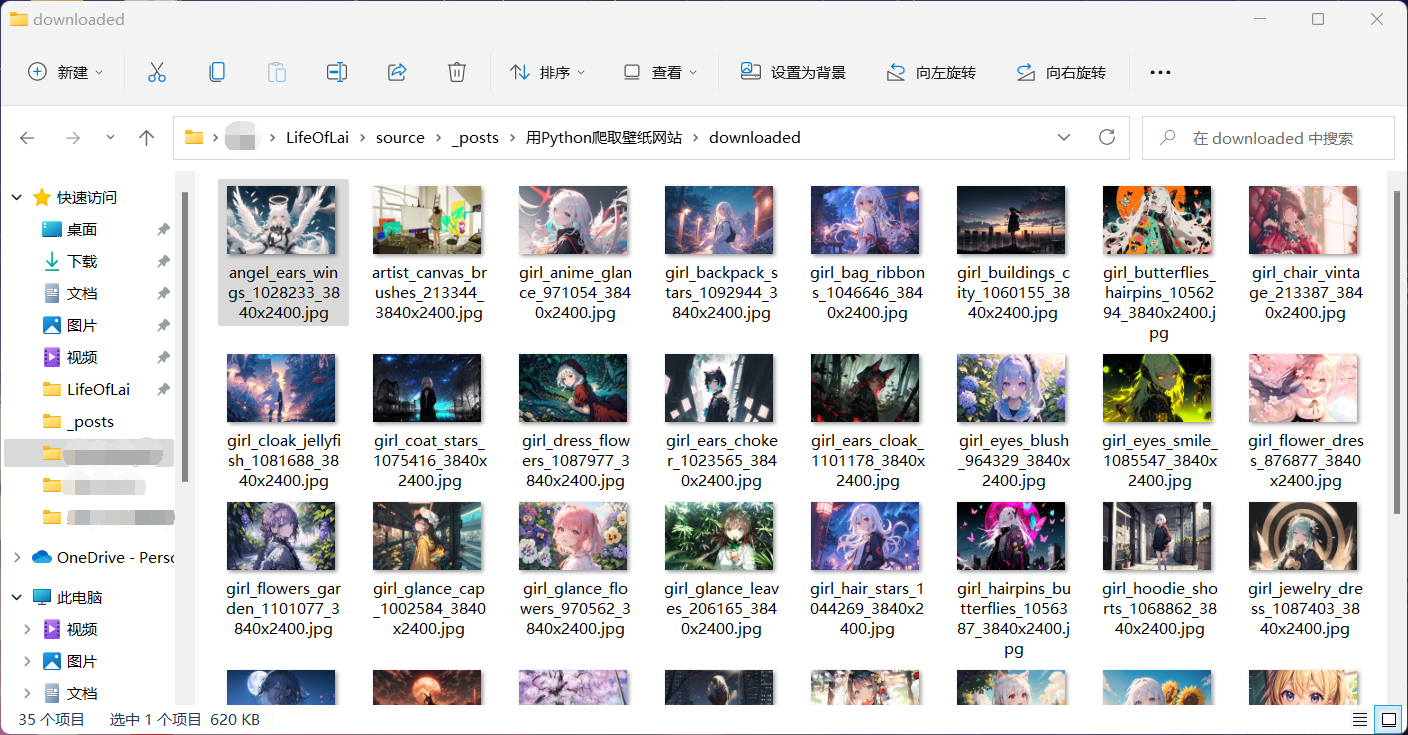 成果.png
成果.png
