初识seaborn
Seaborn is a library for making statistical graphics in Python. It builds on top of matplotlib and integrates closely with pandas data structures.
——An introduction to seaborn — seaborn 0.13.2 documentation (pydata.org)
本文中的图片和供下载的文件都挂载在GitHub上,国内的朋友可能加载慢。
一个简单的例子
完整代码即效果一览
1 | # 导入seaborn和pandas |
<seaborn.axisgrid.FacetGrid at 0x2404088ae20>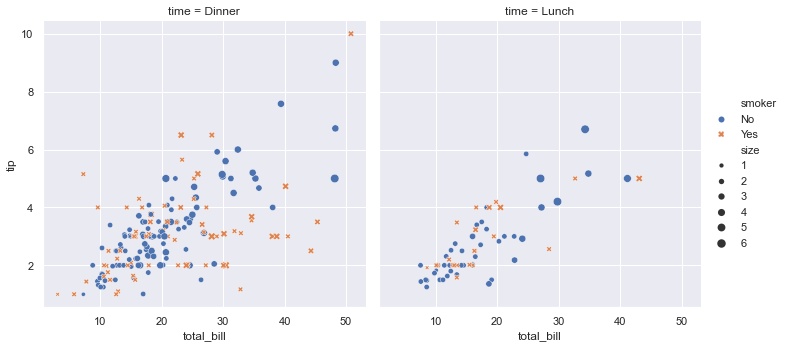
代码拆解分析
1 | sns.relplot( |
这个用函数relplot()图像展示了tips数据集中5个变量之间的关系。注意:我们只是提供了变量的名字。与matplotlib不同,我们不需要说明变量用于颜色或标记(marker)等具体属性,这让我们可以专注于解决具体问题,而非纠结于如何控制matplotlib。
用于统计图标的高级API
世界上没有绝对最好的方法实现数据可视化。不同的问题对应不同的解决方案。seaborn用连续的面向数据集的API使得在不同数据集之间转换变得容易。
函数relplot()由于被设计用于实现不同统计之间的关系(relationships)而得名。函数relplot()有一个kind参数实现不同统计图表之间的简单转换。
1 | dots = pd.read_csv("dots.csv") |
<seaborn.axisgrid.FacetGrid at 0x24042e3f220>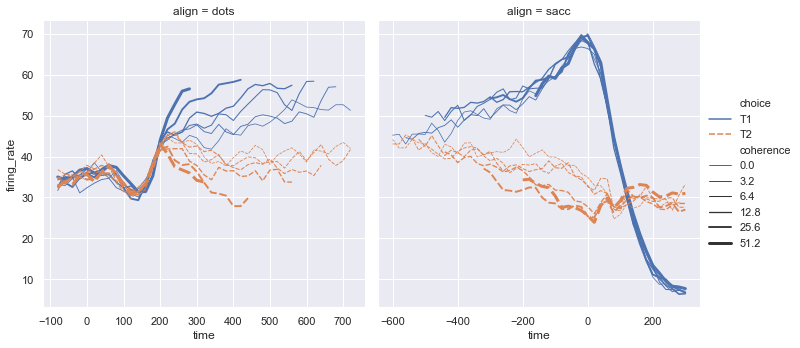
我们注意到size和style参数在散点图和折线图中都有应用,但在两种图中的效果却不相同。散点图中是改变标记点的区域和形状,而折线图中则是改变折线的宽度和虚线。当然,我们不用把这些都记在脑袋里,我们只需要专注于图像的整体结构和我们想要传达的信息。
统计估计
1 | fmri = pd.read_csv("fmri.csv") |
<seaborn.axisgrid.FacetGrid at 0x240441a3940>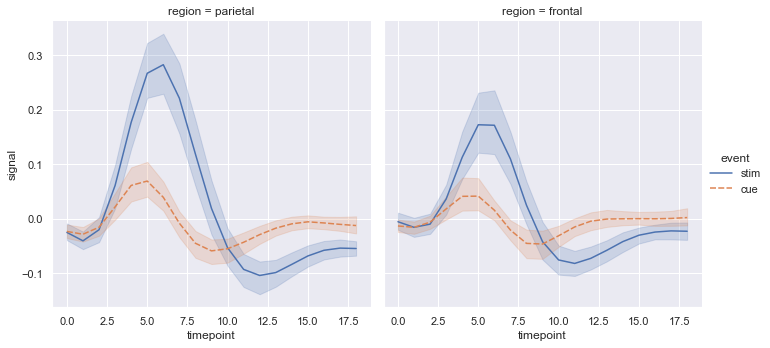
同样,利用lmplot()函数可以绘制散点图的拟合曲线和置信区间。
1 | sns.lmplot(data=tips, x="total_bill", y="tip", col="time", hue="smoker") |
<seaborn.axisgrid.FacetGrid at 0x2404424fa60>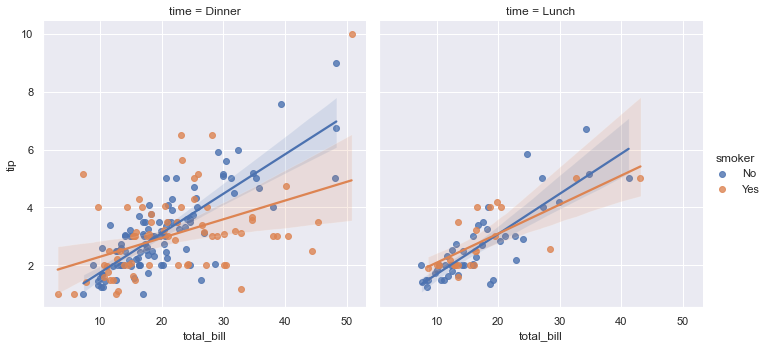
分布展示
函数displot()支持多种实现分布可视化的方法,包括传统的直方图和核密度图等。
1 | sns.displot(data=tips, x="total_bill", col="time", kde=True) |
<seaborn.axisgrid.FacetGrid at 0x240444a3a00>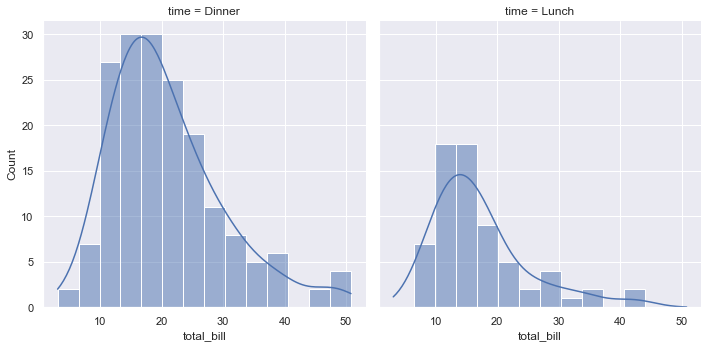
seaborn同样支持强大却不太常见的图表,例如经验分布函数
经验分布函数(英语:empirical distribution function)是统计学中一个与样本经验测度有关的分布函数。该累积分布函数是在所有n个数据点上都跳跃1/n的阶跃函数。对被测变量的某个值而言,该值的分布函数值表示所有观测样本中小于或等于该值的样本所占的比例。
经验分布函数是对用于生成样本的累积分布函数的估计。根据Glivenko–Cantelli定理可以证明,经验分布函数以概率1收敛至这一累积分布函数。
——维基百科
1 | sns.displot(data=tips, kind="ecdf", x="total_bill", col="time", hue="smoker", rug=True) |
<seaborn.axisgrid.FacetGrid at 0x2407f6e0820>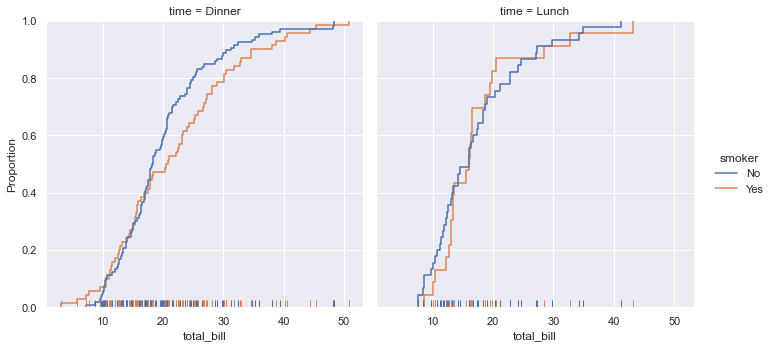
分组数据
seaborn中有几种图像类型面向分组绘图。它们可以使用catplot()函数实现。
1 | sns.catplot(data=tips, kind="swarm", x="day", y="total_bill", hue="smoker") |
<seaborn.axisgrid.FacetGrid at 0x2404694f0a0>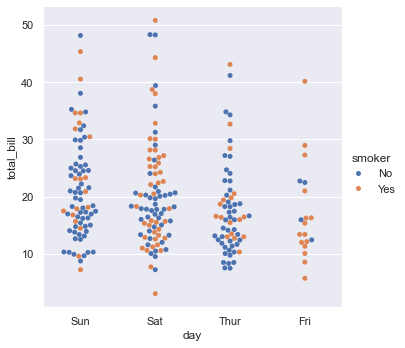
当然,除了散点图,我们也可以绘制核密度曲线,即小提琴图。
1 | sns.catplot(data=tips, kind="violin", x="day", y="total_bill", hue="smoker", split=True) |
<seaborn.axisgrid.FacetGrid at 0x24046968c10>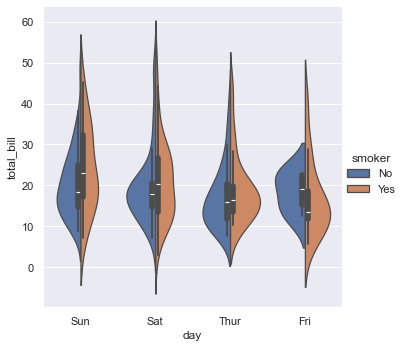
或者,我们可以只展示均值和置信区间。
1 | sns.catplot(data=tips, kind="bar", x="day", y="total_bill", hue="smoker") |
<seaborn.axisgrid.FacetGrid at 0x240469330d0>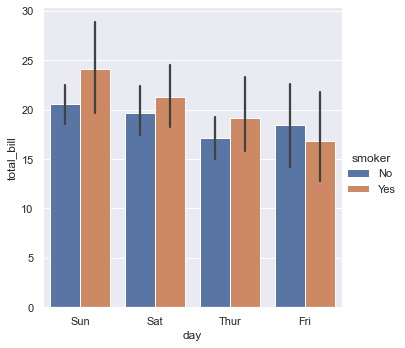
复杂数据集的多维度展示
一些seaborn函数联合了多种图像类型来快速而详实地给出数据集的总结。例如joinplot()函数专注于单一的关系,它可以在变量分布的边缘绘制两个变量的联合分布。
1 | penguins = pd.read_csv("penguins.csv") |
<seaborn.axisgrid.JointGrid at 0x24046cb8100>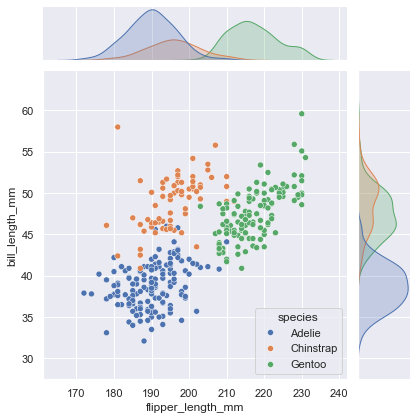
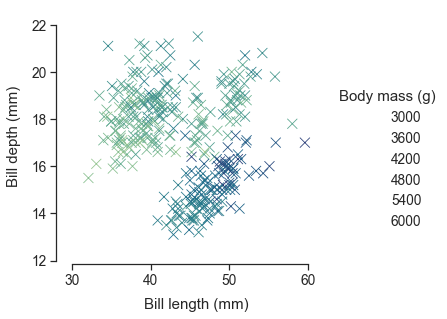
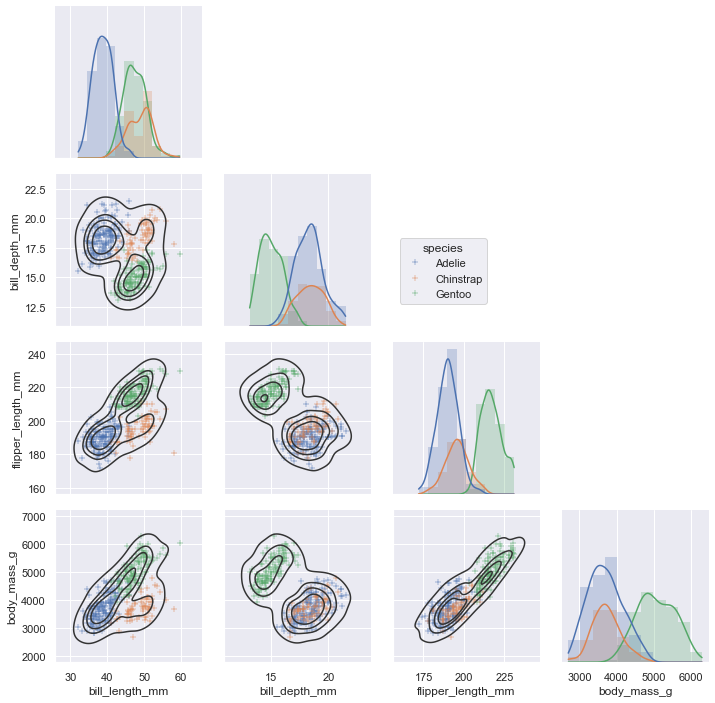
另外一个函数pairplot()则展示了更广的维度:它展示了所有两个变量之间的关系。
1 | sns.pairplot(data=penguins, hue="species") |
<seaborn.axisgrid.PairGrid at 0x24046dc3eb0>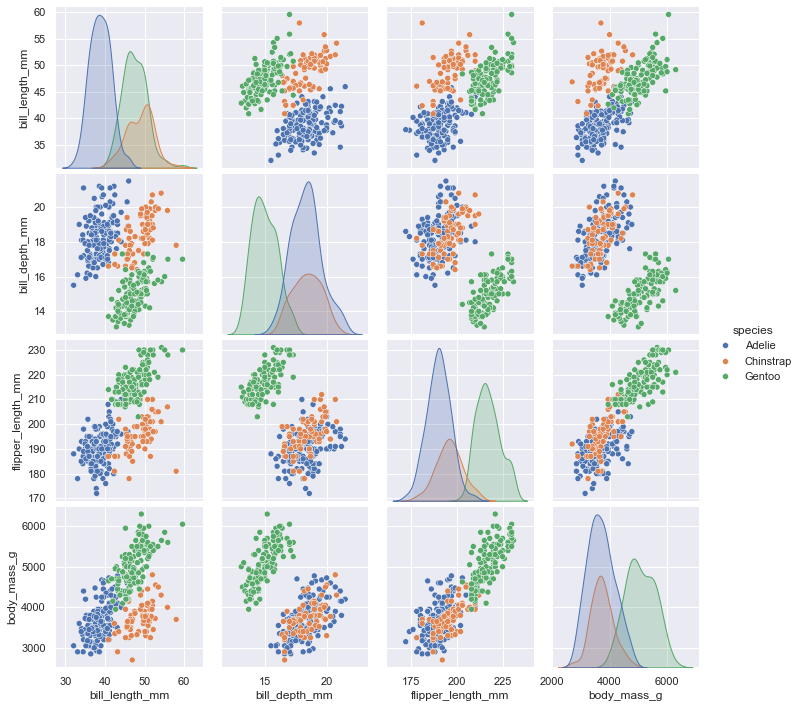
绘图的更底层工具
这些工具的工作原理是将轴级绘图功能与管理图形布局的对象相结合,从而将数据集的结构链接到轴网格。这两个元素都是公共API的一部分,我们可以直接使用它们来创建复杂的图形。
1 | g = sns.PairGrid(penguins, hue="species", corner=True) |
默认与自定义
seaborn只需调用一次函数即可创建完整的图形:它将自动添加信息丰富的轴标签和图例。
在许多情况下,seabon
还会根据数据的特征为其参数选择默认值。例我们映射使用不同的色调(蓝色、橙或有时是绿色)来调的分类级别。在映射数字变量时,某些函数将切换到连续渐变:
1 | sns.relplot( |
<seaborn.axisgrid.FacetGrid at 0x24049087730>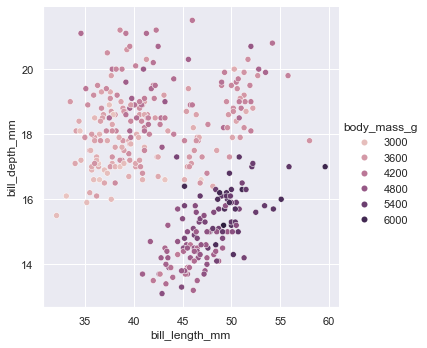
seaborn允许多个级别的自定义。它定义了适用于所有图形的多个内置主题,且具有标准化参数,可以修改每个图的语义映射,并传递给底层matplotlib,从而实现更多控制。创建图像后,可以通过seaborn的API修改其属性,也可以通过底层的matplotlib进行调整。
1 | sns.set_theme(style="ticks", font_scale=1.25) |
<seaborn.axisgrid.FacetGrid at 0x240444b4880>